
You might be using the wrong wording when talking about user findings
The problems that arise from most people not understanding statistics


You might be mistakenly talking about your user research findings like it’s a quantitative study, and you may not even realize it.
It’s not a mistake that you’re making out of malice, and it’s not even entirely your fault. Instead, it’s a mistake in communication because most people don’t understand statistics.
Imagine that you’ve finished user testing with a small group of 8 participants. You’ve seen multiple users (or even the majority of them) make the same mistake or provide the same usability suggestion. But you feel like saying “6 out of 8 users did X” or “7 out of 8 users wanted Y” for every slide is a little wordy. You might be tempted to condense it into a percentage like “75% of users.” But that’s a mistake for one crucial reason: your audience will misinterpret that as a quantitative metric.
Your audience will likely generalize any statistical claim you make to apply to your entire user base, so you can’t make any statistical claims in a qualitative study without caveats.
To understand why this is a problem, we first need to understand the difference between qualitative and quantitative studies.
Qualitative vs. quantitative studies

https://blog.optimalworkshop.com/a-beginners-guide-to-qualitative-and-quantitative-research/
You’re probably familiar with one of these methods if you do user research, but you may not be familiar with both of them.
Qualitative studies are about asking the question, “Why?”. We conduct user testing or interviews to gather observational findings that identify design features easy or hard to use. We’re assessing participants directly and interacting with them throughout this process. As a result, we only need a handful of representative users (as few as five) to accomplish this.
Quantitative studies, on the other hand, are about asking the question “How Many?” We want to gather one or more metrics (such as task completion rates or task times) that reflect whether the tasks were easy to perform. We need to gather metrics that we can benchmark or compare against. As a result, we need to have enough users to represent our entire user base and show statistical significance. As a result, we need to have at least 20 users, but more realistically, we need 30 or 40.
To sum it up, Qualitative studies are for insights, and Quantitative studies are for metrics. So you should never use terms or language that might confuse the two. The reason for this is simple: people don’t understand statistics.
The problem with statistics
Imagine if a non-UX team member came up to you and said they did a quick UX test and found a design that works for 100% of users they tested. Wouldn’t you be suspicious?
Assume they aren’t lying completely. You might dig a little bit further and immediately see the problem. The design indeed works for 100% of users tested, but it’s just him and his buddy Steve, who have duplicate job titles and training. In other words, it’s a sample size of 2.
We’re trained to look for these things with user research, so we know this is a red flag. But imagine that we’re reversing the situation and presenting it to your team.
When you say “75% of users” to your team, do your team interpret that as…
6 out of 8 users you tested with? Or,
75% of all users, which means that our finding would be representative of possibly millions of users?
This example seems outlandish because there’s no way you tested with millions of users. But using a statistical measure like a percentage implies that things will scale at a similar interval.
You might say ‘The average satisfaction rating in our study was 6.7 on a scale from 1 to 7’, but your stakeholders will likely hear ‘The average satisfaction rating for all our users is 6.7.’
This applies to many statistical measures:
Percentages (60% of users…)
Averages (Average time on task is…)
Comparisons (Ease-of-use rating is better in design X (6.2) than in Design Y (5.4))
Even if you’ve gathered participants that are a good mix of different roles, likely, you haven’t recruited enough users for your results to:
Be representative of your entire user base
Be statistically significant
So what should you do instead?
Avoiding statistical confusion
So what should we do instead of saying things like this? There are three approaches, and they require different amounts of effort. Use individual, not aggregated, values as additional evidence in your stories/anecdotes. The most straightforward option is to use these individual values as additional evidence rather than aggregated data. You can do this to communicate the severity of usability problems.
For example, “Our participants spent a lot of time trying to figure out how to reset their passwords. One participant spent 11 minutes on this task, sending multiple password reset requests because she wasn’t sure if the button did anything.” In this way, we contextualize an individual value (“11 minutes”) within the larger story to suggest the task's difficulty.
We can’t use an aggregated statistic (i.e., “participants had an average time of 6 minutes 33 seconds”) because we don’t have enough participants for statistically significant data. However, we can still use the individual value.
This adds a quantitative layer to the evidence we’re presenting without resulting in issues that one might recognize when there are issues.
Use the System Usability Scale (SUS) survey.
If you need a metric for qualitative studies, use the System Usability Scale (SUS). In case you’re not aware, the System Usability Scale is a 10-item questionnaire that, when calculated, allows you to calculate the usability and learnability of a website or application. The System Usability Scale (SUS) has been tested and is considered reliable for small sample sizes. Some organizations report SUS results for as few as five users.
However, when deploying the SUS for small numbers of users, you need to keep in mind that you’re not getting the exact number: instead, you’re getting a ballpark figure.
For example, if the actual SUS figure was 74, you might get SUS scores from your participants ranging from 66 to 80 with five users 50% of the time. But this can still be helpful to get a general sense of how users perceive your product and a valid way of using percentages. In this case, we have a benchmark (68) that we can measure against everything. With the SUS, anything above 68 is considered above average and below 68 is considered below average. But we can also normalize them into percentages or assign them as letter grades. So with the example of the 74, we might say it’s the 72nd percentile or give it the letter grade “B.”
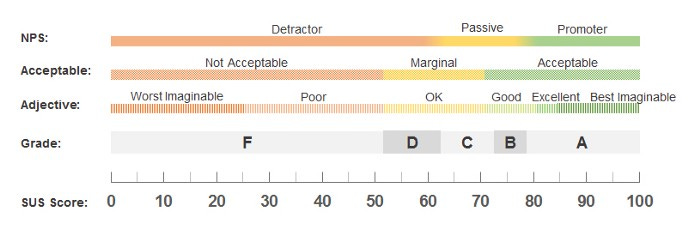
https://measuringu.com/interpret-sus-score/
Or, if you’re invested, you can also look at the metrics.
Review analytics data for support (and triangulation)
If your website or application is public-facing, you might be able to access Google Analytics data regarding some of these metrics. Many of these metrics currently exist within the system and maybe the driving force behind user research or UX Design.
In this case, aligning a current problematic metric with what you’ve seen within the user research can suggest that this may be why there’s an issue. This serves the same purpose as the mistake (implying that most participants ran into a problem), but it does with a more extensive, valid, and reliable participant base. For example, “Our participants seemed to struggle with the reset password task, taking anywhere from 6 to 11 minutes to complete this task. We had a limited sample of users, but we found that the average time spent on our Reset Password page was 9 minutes when we looked at Google Analytics. As a result, we may want to address this user finding with high priority. ”
You cannot trust numbers in qualitative usability studies
Language matters when it comes to how we present the data.
You may be excited that you’ve found the primary cause of a usability problem that all participants spoke about. However, you still have to remember that they’re not a perfect representation of all of your users. So using language that suggests that your results would scale perfectly is a mistake.
Sample size matters a lot: the methods and results that work on five users won’t necessarily work for 40 users. So avoid the temptation to use generalizing language that might suggest otherwise.
Kai Wong is a UX Specialist, Author, and Data Visualization advocate. His latest book, Data Persuasion, talks about learning Data Visualization from a Designer’s perspective and how UX can benefit Data Visualization.